Bringing together a decade of artistic responses to machine vision, face recognition, and generative models, Antonio Somaini’s The World Through AI at the Jeu de Paume in Paris, stood out among last year’s plethora of AI-themed exhibitions. In the following interview, which took place ahead of his lecture “Latent Spaces: AI, Art and the Archive” at the Seminar of Aesthetics, University of Oslo, Somaini makes a case for why artists are essential to understanding how AI is impacting culture.
Somaini is professor of film, media, and cultural theory at Université Sorbonne Nouvelle in Paris. His recent academic research on AI and visual culture is closely tied to his curatorial work. He finds in contemporary art a site where the political, infrastructural, and perceptual dimensions of AI become legible in ways theory alone cannot achieve.
Your earlier work was focused on montage theory, on editing as a way of thinking and the production of knowledge through juxtaposition. What prompted the shift toward AI?
My interest in AI and more specifically in the impact of AI algorithms and models on images and visual culture started in 2017 when I read an article by Trevor Paglen entitled ‘Invisible Images: Your Pictures Are Looking at You’. He was writing about machine vision, discussing the presence throughout visual culture of this non-human machinic gaze that had a whole series of applications in terms of surveillance, control, and so on. And in one of the passages of that essay, he wrote that “if we want to understand how machine vision works, we need to unlearn how to see like humans.”

That phrase resonated deeply because at the time I was working on the French edition of Dziga Vertov’s writings from the 1920s and 30s about how photography and cinema had introduced a form of non-human vision that displaced and repositioned the human gaze. We find it in Vertov’s “Kino-Eye” [the title of a 1924 film that has also become a theoretical concept], the camera as a mechanical eye more perfect than the human eye; in Siegfried Kracauer’s writings on photography in 1927; in László Moholy-Nagy’s idea of photography as an indifferent vision detached from human affects; and in Walter Benjamin’s concept of the optical unconscious. So Paglen’s phrase opened a direct line between that earlier history and the present. This has now been my main research focus for almost ten years.

I became aware of your work with AI models when you co-organised the conference ‘Cut/Generate’ in Paris. The title names two quite different operations. What is at stake in that distinction?
The idea was to try to understand the new typology of moving images that generative AI models have introduced – whether the Generative Adversarial Networks [GANs] at the end of the 2010s or the diffusion models used now. How are these moving images produced technically, what kind of temporality do they convey, and what new forms of montage are artists and filmmakers using? ‘Cut/Generate’ pointed to a significant difference between the operation of the cut in an analog film or a digital video file and the operation of image generation, which does not stem from any form of optical capture but from prompting and combining prompts and images.
I’ve seen a lot of recent artworks that use generative AI, but many of them – like sound pieces or films that change every time they are played – could have been made with much simpler algorithms. These forms already existed with Fluxus, with people like John Cage or Brian Eno. So, when you curate, what kind of AI work interests you, and how do you distinguish it from these earlier algorithmic practices?
What I’m interested in is artists who tackle AI from very different perspectives and media, but with a critical stance – critical meaning not only negative, but reflective, conceptual, aware of the social and political implications of these technologies. In the Jeu de Paume exhibition, the works came from the last ten years, from 2015 to the present. But I also included a series of “time capsules” – vitrines containing objects, technical devices, books, and photographs from other historical periods that provided a genealogical perspective onto the present.

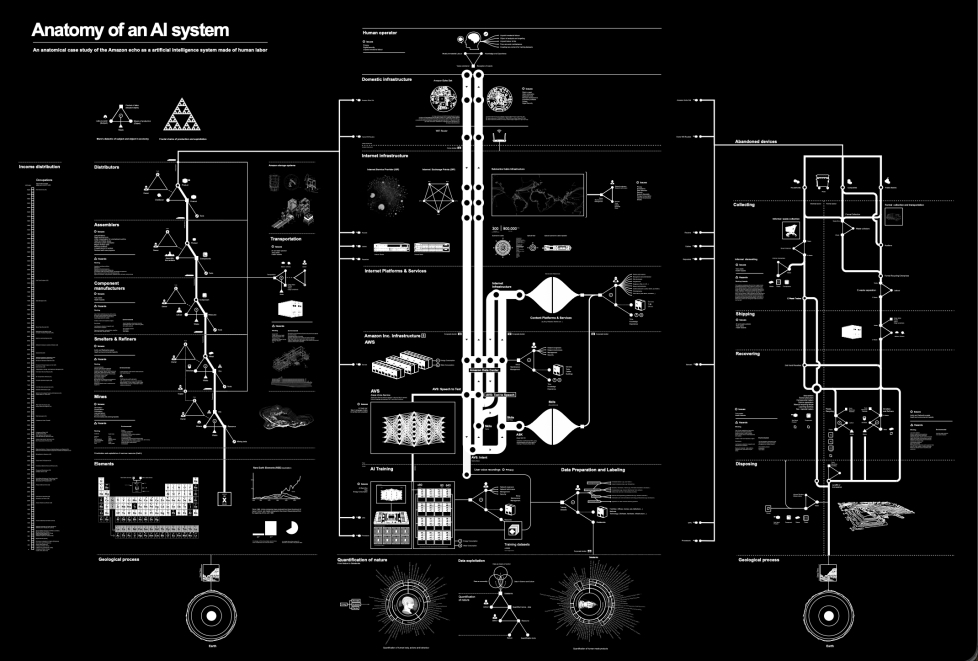
The Jeu de Paume exhibition included works dealing with the material infrastructure of AI, like Hito Steyerl’s Mechanical Kurds [2025] or Agnieska Kurant’s Aggregated Ghosts [2020], both of which bring attention to the human labour that goes into AI, alongside more speculative works. How did you think about those different registers curatorially?
Kurant and Steyerl, but also Paglen’s Behold These Glorious Times! [2017] and Kate Crawford and Vladan Joler’s Anatomy of an AI System [2018] dealt with different layers of the AI infrastructure, the very complex stacking of processes and labor: extraction, energy, micro-labor, training sets.And then there were works that had a more speculative dimension – thinking about how AI changes our perception of time, of the past, the future, the present. These are not about the AI infrastructure, but about AI as a space of possibility and impossibility. Holly Herndon and Mat Dryhurst’s xhairymutantx [2024], for instance.
We also had a section exploring the intersections between large language models and literature. Gregory Chatonsky’s installation The Fourth Memory [2025] was a good example – a generative video endlessly produced without ever repeating itself, where each image was immediately described by an image-to-text model, and the text was then read by an AI-generated voice – a whole loop between words and images. AI is really reorganising the relations between images and words.
There has been a barrage of AI-themed exhibitions recently, but I also see a lot of exhibitions that go in the opposite direction, that foreground craft and hands-on processes. Is that also a form of critique, in your view?
Absolutely, it can be a form of critique. But it is a critique that decides to ignore AI, or to treat it in terms of absence, whereas the exhibitions I’m trying to develop tackle AI frontally. They try to make its functioning more transparent, but also sometimes to suggest other forms of AI, as in the case of the entire work of Holly Herndon and Mat Dryhurst during the last few years. Right now the commercial AI field is dominated by a handful of US companies, all more or less aligned with the Trump administration. The political stakes are enormous. And these artistic attempts to show that AI could be conceived and developed otherwise are very important.
The concept of a latent space, the compressed mathematical representation of everything a model has been trained on, is central to your thinking on AI. As more of our cultural memory is organised by these processes, how do they reshape what becomes visible and what is left out?
We’re now in a situation where all the cultural objects that exist in digital form on the internet eventually end up in training sets for AI models. And there’s not one kind of latent space, but many different kinds depending on the model. What they have in common is that once they’ve been given the digital data contained in training sets, they compress all this material into a vector space. So a latent space is a kind of compressed vectorial representation. It captures only what was present in the training data. The compression filters out data that were more marginal, less represented. So latent spaces are a system of inclusion and exclusion that prolongs the power dynamics archives have had historically, except that it does so not on the basis of human or institutional intentions, but on the basis of mathematical operations. That’s why it is crucial to understand them, so that these operations of inclusion and exclusion become more transparent.

With something like Paglen and Crawford’s Excavating AI [2019], where they showed how ImageNet’s training dataset sorted images of people into racist and dehumanizing categories, these biases become legible. You can see how the categories were constructed. But a latent space is far more abstract, making it even harder to understand how history is being processed.
Yes, but we still need to work to better understand latent spaces, to make them more interpretable. For this, we in the humanities need to learn to be in dialogue with computer scientists. Right now there’s not much dialogue between the two fields, and that’s not only the humanities’ fault. Computer scientists often look at these models only in terms of how to improve them and are not so interested in their cultural implications. There’s a real need for transdisciplinary dialogue, and a need to bring into the humanities concepts such as vectors, latent spaces, alignment, training, hallucinations.
These are concepts with histories that long predate AI. The notion of hallucination completely predates it, and the term “latent” is full of implications linked to psychoanalysis, medicine, analog photography, as in the “latent image.” We need to work with these concepts. And at the same time, as I argue in the essay ‘Algorithmic Images’ [2023], these new phenomena lead us to rethink older concepts, such as the very concepts of image and vision. Today we may legitimately ask ourselves what is an image, when an image can be analysed by machine vision systems even when it is not visible to human eyes, when it exists only as a digital file.
Are there questions from the exhibition at Jeu de Paume that you feel you need to expand on, or has the landscape shifted so much since then that you’re working with entirely new concerns?
The Jeu de Paume exhibition will be presented in new versions in Frankfurt [at the Schirn Kunsthalle, opening 10 June] and São Paulo [at the SESC 24 de Maio, opening 5 August], and I seized the opportunity offered by these new iterations to tackle new topics, such as the rise of AI slop and the phenomenon of AI “slopaganda,” and to give more visibility to topics that were already present at the Jeu de Paume, such as the decolonial approaches to AI. The next exhibition I am working on will open in September 2027 in Lisbon at the Museum of Art, Architecture and Technology, the MAAT – a museum partially located in what used to be the city’s main power plant. So I decided to focus on the question of energy. It’s going to be called Energies of AI, and there will be a large new project by Crawford and Joler called Metabolic Machines, which deals with AI technologies as metabolic technologies that ingest vast quantities of energy, natural resources, and data.
It will be a very different exhibition from the one at the Jeu de Paume, less about the representation of the past and more projected towards the future. I will also have new works that try to shed light on where AI technologies might be heading. One is a project by Herndon and Dryhurst called Kinder Scout, which deals with AI agents, models not based on question-response but who [sic] have higher degrees of autonomy. Visitors will see AI agents trying to produce genuinely new images, not variations of existing ones, with other agents pushing them towards newer and newer outputs.